앞 포스팅에 이어서 Azure 머신러닝관련 포스팅을 더 쓰겠음
앞내용은 아래링크에서 확인할수있다 !
[Microsoft Azure] Azure Machine Learning 머신러닝 생성, 스튜디오 사용법
오늘은 타이타닉생존자들의 데이터를 분석해서 새로운 인사이트를 파악하는 애저의 머신러닝기능을 포스팅할것임 머신러닝은 데이터를 기반으로 학습 또는 성능 향상을 지원하는 시스템을 구
tok5.tistory.com
< 훈련,검증용 데이터 분리 >

훈련데이터와 검증데이터 분리를 위해 split data블럭을 만들것임
Splitting mode : Split Rows
Fraction of rows in the output dataset : 0.7로 수정 ( 반반인 0.5로하는게아니라서 다른한쪽은 0.3이 됨)
Radom seed : row를 랜덤하게 추릴수있게 해줌 ( 원래 항상할때마다 무작위로해야하는데, 실습이여서 2로 정함, 2로 하면 랜덤하지만 결과는 동일함)
이제, 어떤 머신러닝 알고리즘을 적용해서 분석할지 결정해야하는데
아래링크의 two class 알고리즘을 쓰겠다
다양한 알고리즘이 있는데 상황에 맞는 알고리즘을 쓰기엔 전문가가 아닌이상 모르기때문에 azure에서는 치트시트 제공함 !
https://learn.microsoft.com/ko-kr/azure/machine-learning/algorithm-cheat-sheet?view=azureml-api-1
Machine Learning 알고리즘 치트 시트 - 디자이너 - Azure Machine Learning
인쇄 가능한 Machine Learning 알고리즘 치트 시트를 사용하면, Azure Machine Learning 디자이너에서 예측 모델에 적합한 알고리즘을 선택할 수 있습니다.
learn.microsoft.com

Two-Class Boosted Decision Tree 블럭은 알고리즘만 있는 블럭이라서 따로 수정안함
알고리즘 수행블럭이 있어야하고, 알고리즘 검증은 cross validate에서 한다
데이터를 10개,20개로 나눠서 하나를 검증으로 놓고, 나머지는 훈련하는 용도로 놓음
ex) 1번검증, 2~10번을 훈련
2번검증, 1, 3~10번을 훈련
-> 총 10번검증함 이것을 텐폴드라고 함
Split Date의 훈련용데이터를 Cross Validate Model에 입력으로 넣어주고
Two-Class Boosted Decision Tree의 Untraind model을 Cross Validate Model로 연결해서 검증한다
Cross Validate Model블록을 더블클릭해서 열편집- 열이름을 survived로 입력후 저장한다


우측상단에 구성 및 전송을 클릭해서 테스트하겠음

Cross Validate Model이 어떤식으로 결과를 만들어낼지 확인해볼건데,
Cross Validate Model 블록위에서 우클릭 - 데이터 미리보기 - Scored results 를 보면 아래같은화면이 나온다
아래는 훈련데이터로 검증데이터를 유추한것임

데이터미리보기 - Evaluation results by fold
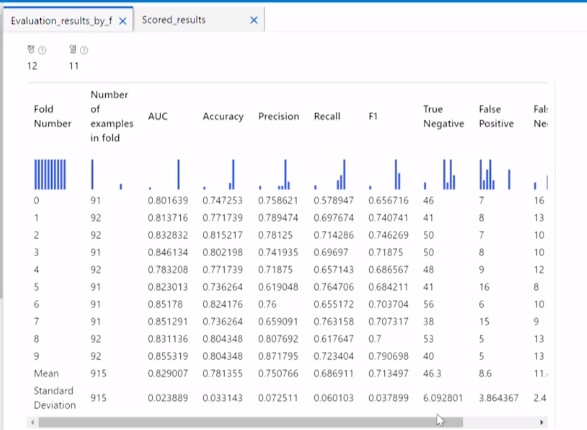
fold별로 Accuracy가 70 80%라고 나타났는데, F1을 보면 대략적으로 70~75% 의 성능을 보임
=> 제대로된 알고리즘을 적용했다는걸 알수있음
일단 Cross Validate Model은 옆으로 제껴두고,
데이터를 훈련시켜서 나머지 30퍼 검증데이터통해서 얼마만큼 정확도가 향상되었는지 알아보기위해
Train model블럭을 이용하기위해 추가할것임
Two class의 훈련되지않은 모델을 Train model의 왼쪽인 Untrained model에 연결하고,
Split Data에서 훈련시키기로한 데이터 왼쪽 Results datas를 Train model블럭의 Dataset에 화살표연결시켜주겠음

추가로 정확히 분석됐는지 수치화하려고 score블록을 밑에 추가하고,
Train model 의 훈련된것이 Score Model로 들어가게 화살표연결해준다음
Split Data의 오른쪽동그라미인 Result datas(훈련된 모델이 정확한 기능을 했는지 확인하기위해서 검증하기위한 데이터의 나머지 30퍼센트) 를 Score Model 의 Dataset에 화살표연결해준다
시각화해서 평가할수있는 Evaluate Model도 추가하겠음
Train model 블록 더블클릭해서 지금 훈련할때 어떤걸가지고 라벨링할건지 적어주면됨
지금은 survived로 할거라서 저장했음


알고리즘(Two class)을 배치시키고, Train 모델로 훈련시키고, 남겨놓았던 70퍼센트의 데이터가 Train 모델에 입력되고, score모델로 수치화시키고, 이걸 검증할 검증데이터도 Dataset에 같이넣어주고, 그 결과를 Evaluate모델에 넣어주면 최종적으로 시각화까지해서 전반적으로 어떤식의 성능을 하는지 파악가능함
이전처럼 구성 및 전송 - 세부정보보기 들어가서 확인하면되는데

일단 Score Model에서 우클릭-데이터미리보기-Scored dataset눌러서 보면
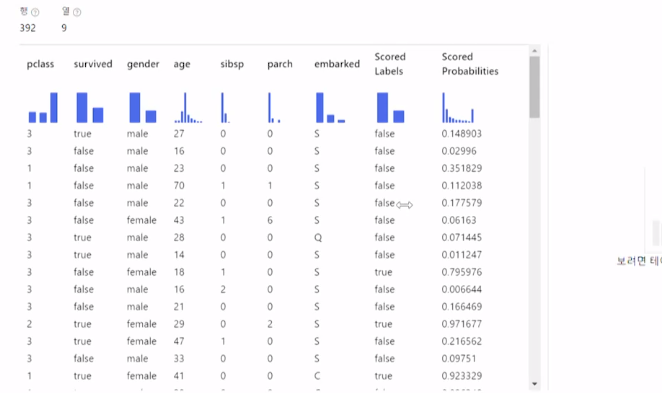
0.5이상은 생존(true), 미만이면 사망(false)으로 판단해서 Scored Lables 에 나타내는데
데이터 약400개로 했는데, 안맞는것들도 있어서
Evaluate 모델도 이용한것임!
이번엔 Evaluate Model에서 우클릭-데이터미리보기-Evaluation results 눌러서 보면



F1점수가 최대값이 되도록 맞추는게 좋음
임계값이 대략 0.52정도면 F1점수가 최대값이된다
=> 이런작업을 통해 추가작업을 어떤식으로 해야 점수를 높일수있는지 방향성을 파악할수있음
머신러닝 디자인화면에서 복수계의 모델을 비교,분석도 가능하고
직접 데이터를 집어넣어서 훈련한 모델이 임의로 만든로 만든 데이터를 어떻게 분류하는지도 파악할수도 있음
분석에 사용한 데이터는 정재화교수님 깃헙에서 참고가능함
https://github.com/jaehwachung/cloud_computing/tree/main/data_analysis

끝
좋아요 댓글 환영
'백엔드' 카테고리의 다른 글
| [IntelliJ] 인텔리제이 try catch / if else / while / for / 코드블럭 단축키 (1) | 2024.03.18 |
|---|---|
| [Microsoft Azure, Python] Azure 함수앱, 날씨API를 이용하여 파이썬으로 일기 예보 전송 서비스 구현하기 (0) | 2023.12.26 |
| [Microsoft Azure] Azure Machine Learning 머신러닝 생성, 스튜디오 사용법 (0) | 2023.12.24 |
| [Microsoft Azure] 애저 Azure Scale Sets 구축하기 (오토 스케일링) (1) | 2023.12.22 |
| [Microsoft Azure] Azure 로드밸런서 구축 (0) | 2023.12.20 |