오늘은 타이타닉생존자들의 데이터를 분석해서 새로운 인사이트를 파악하는 애저의 머신러닝기능을 포스팅할것임
머신러닝은 데이터를 기반으로 학습 또는 성능 향상을 지원하는 시스템을 구축하는 데 초점을 맞추는 인공 지능(AI)의 하위 집합이라고 하는데,
=> 쉽게말해서 사용자가 사용하는 여러 데이터를 분석해서 새로운 인사이트를 파악해서 성능을 향상시키는 기능임
< Azure 머신러닝 생성 >
만들기 - 새작업영역클릭
나는 타이타닉 탑승자 데이터를 파이프라인형태로 머신러닝작업을 해보겠다

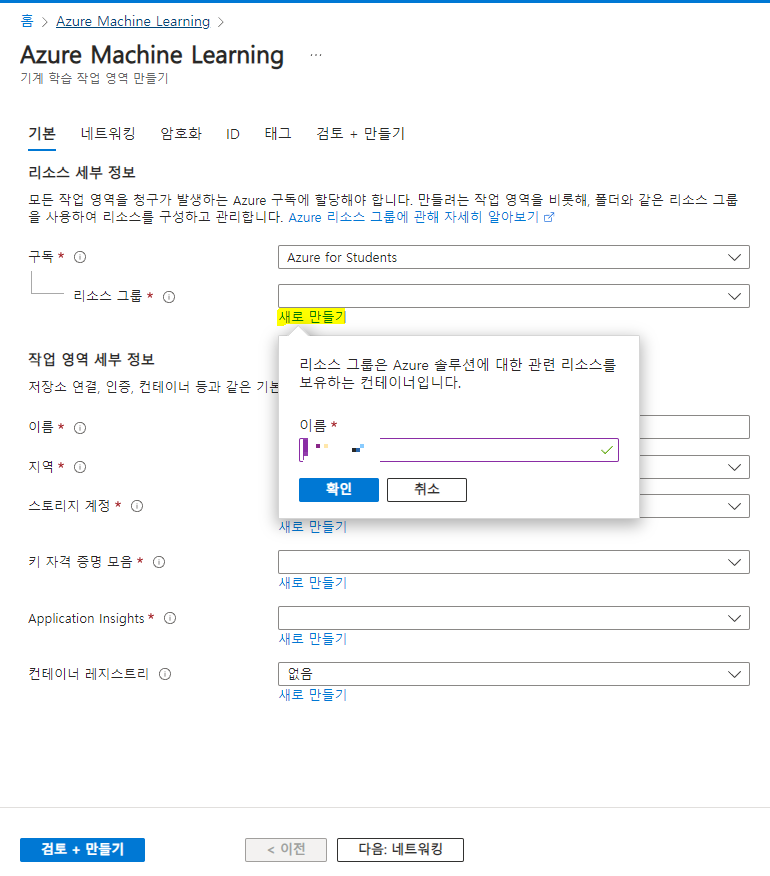
머신러닝은 이름,지역을 입력하면 스토리지,키자격증명모음,인사이트는 자동으로 생성됨
But, 컨테이너는 자동생성이 안되서 새로만들기를 눌러서 직접생성해야함
참고로 컨테이너는 도커기반임
새로만들기를 눌러서 컨테이너를 만들어준다

SKU : 컨테이너의 단위
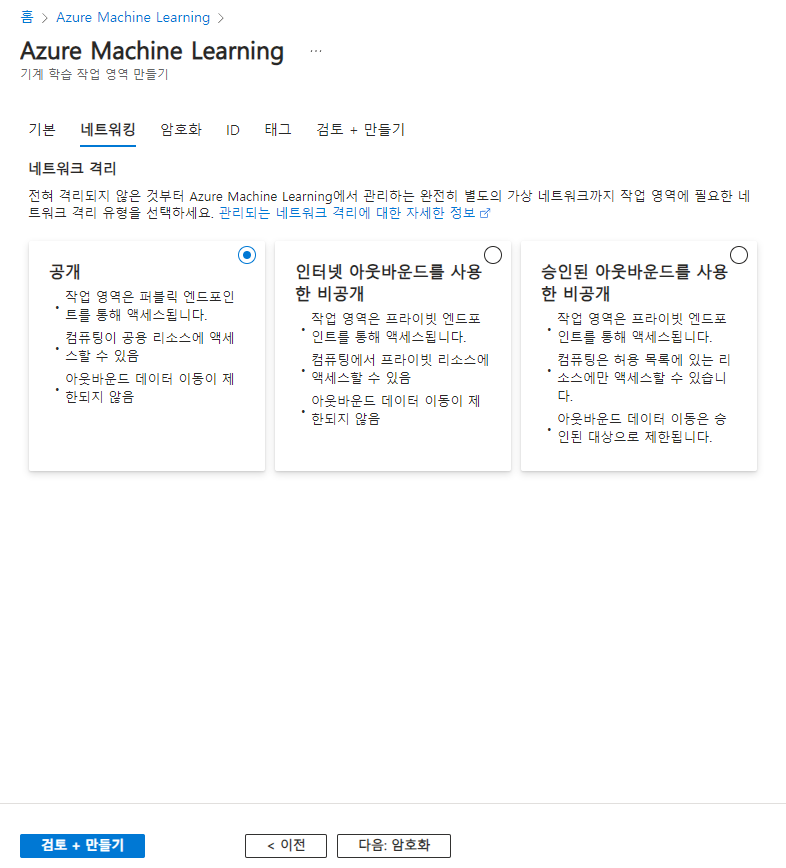
아웃바운드,인바운드 설정안하고 간단하게 작업할거라 네트워킹탭은 공개를 선택후 다음을 눌렀음!
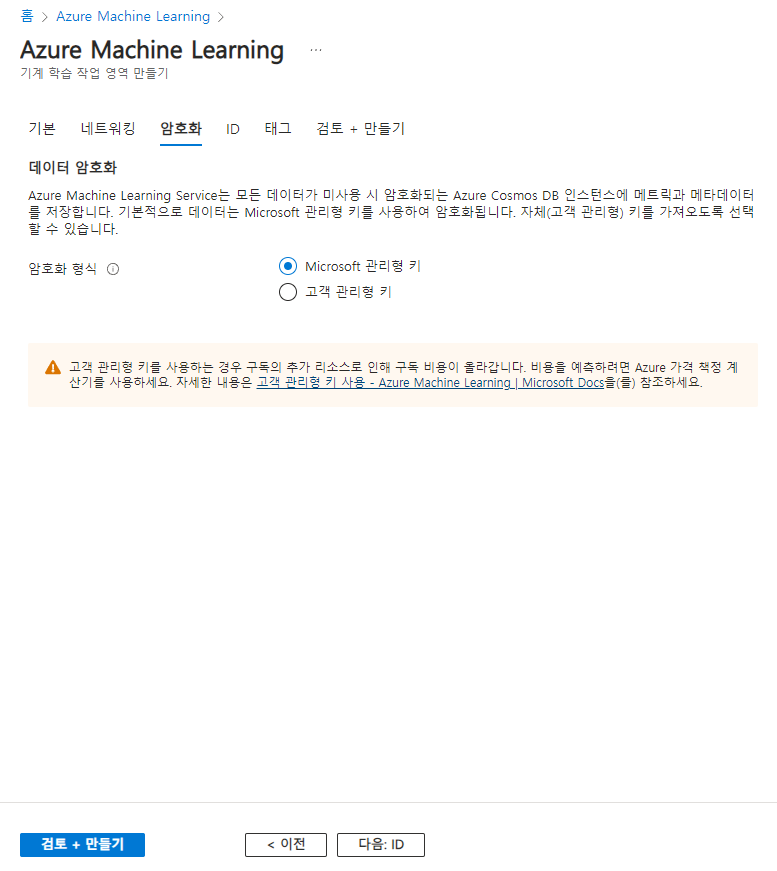
암호화도 마찬가지로 마소에서 제공하는 관리형 키를 선택할것임
ID,태그탭도 마찬가지로 따로 설정안하고 다음
배포가 완료되면 리소스로 이동클릭
누르자마자 보이는 개요탭에 Studio 시작하기 버튼을 클릭해서 가이드를 확인할수있다
한국어설정은 설정탭들어가서 바꿀수있음
자, 이제 인스턴스를 만들어보자 !
스크롤내리다보면 컴퓨팅 인스턴스라는 항목이 보이는데 + 버튼을 클릭한다
그럼 아래화면이 뜨는데, 이름,유형,머신크기를 선택후 쭉쭉 진행하면됨
나는 걍 바로 검토+만들기를 눌렀음
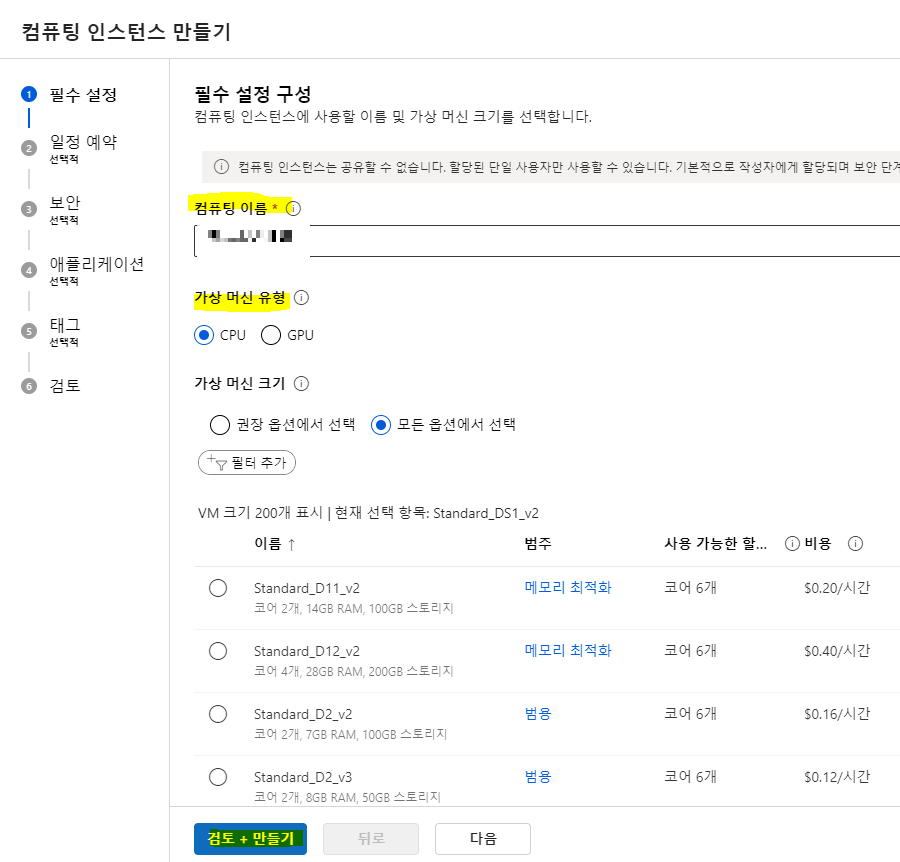
가상머신유형이 GPU면 좋겠지만 과금이 상당히 비싸서 CPU선택 ㅋㅋㅋ
과금폭탄이 무서워서 모든옵션에서 선택을 눌러서 저렴한걸로 골랐다 어차피 실습목적이니까,,,ㅎ
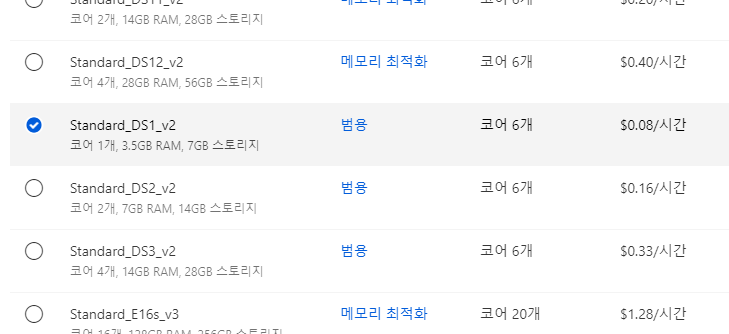
인스턴스가 만들어지면 맨위 우측에 새로만들기 버튼을 클릭해서 사용할 형태를 선택해준다
굉장히 많은 자원들과 기능들을 사용가능한데 나는 파이프라인형태로 만들어볼까함!
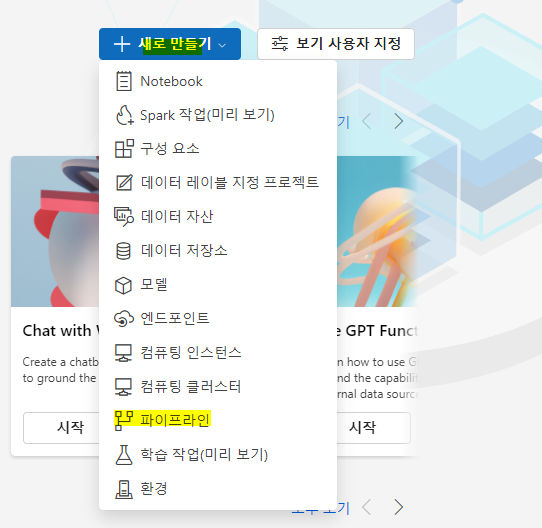
파이프라인을 선택후 아래그림처럼 +버튼을 눌러서 생성해보겠음
데이터탭을 누르면 어떤 데이터들로 분석할건지 선택할수잇음

파일로부터 데이터를 읽어온 데이터를 내가설정한 이름 ㅇㅇㅇ으로 할것이다 라는뜻
다음을 누른후 나는 웹파일에서 작업할거라서 선택후 다음클릭함


URL입력후 다음클릭함
만약 깃헙에서 파일을 가져오는거면 원본csv파일을 넘겨줘야하기때문에 Raw클릭후 복붙해서 URL넣어야함
https://github.com/jaehwachung/cloud_computing/blob/main/data_analysis/Titanic_dataset.csv
(정재화교수님 깃헙데이터참고)
만들기눌러서 생성해준다
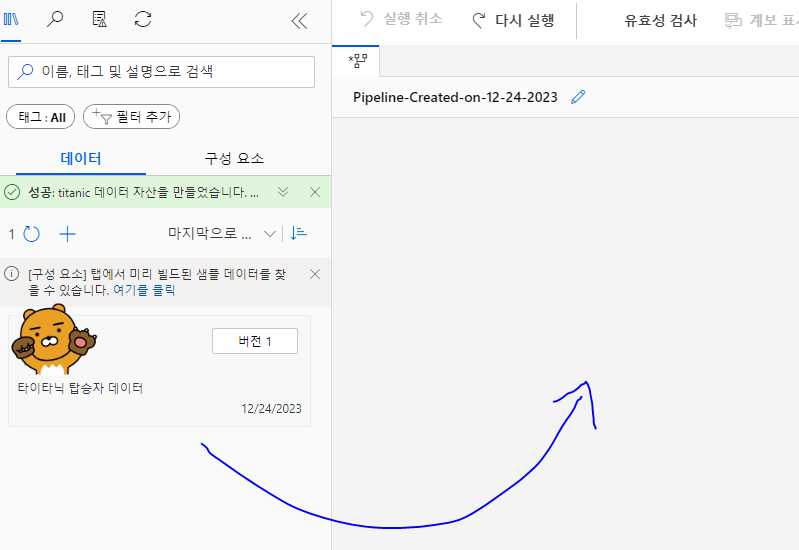
생성후에 드래그해서 오른쪽에 끌어놓으면, 파이프라인의 첫시작을 만든것이다 ㅎ
이것으로 구성요소에서 여러가지 조작을 할수있음
타이타닉 탑승자 데이터 중에서 필요한 데이터를 구분하기위해 전처리 과정작업을 해야함
전처리과정 : 필요한데이터인지 아닌지 구분하는 작업

구성요소에서 Data Transformation 버튼을 눌러서 쭉쭉 스크롤내리다보면 Select Coumns in Dataset을 찾을수있다 ㅎ
이놈을 드래그해서 아까처럼 오른쪽영역에 끌어놓고 아래그림처럼 위의 동그라미에서 아래동그라미로 드래그하면, 화살표가 생성되면서 연결됨
=> 타이타닉데이터를 Select Coumn 에 집어넣어서 필요한 컬럼만 사용할수있게됨
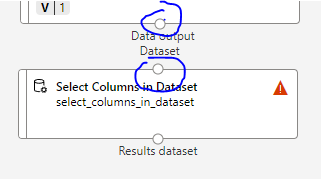

빨간세모는 아직 컬럼설정을 하지않아서 뜨는것으로 더블클릭해서 설정가능함
더블클릭하면 아래같은 창이 뜨는데 열편집을 눌러서 내가 원하는 열을 편집할수있음
파란동그라미부분은 닫기임ㅋㅋㅋ
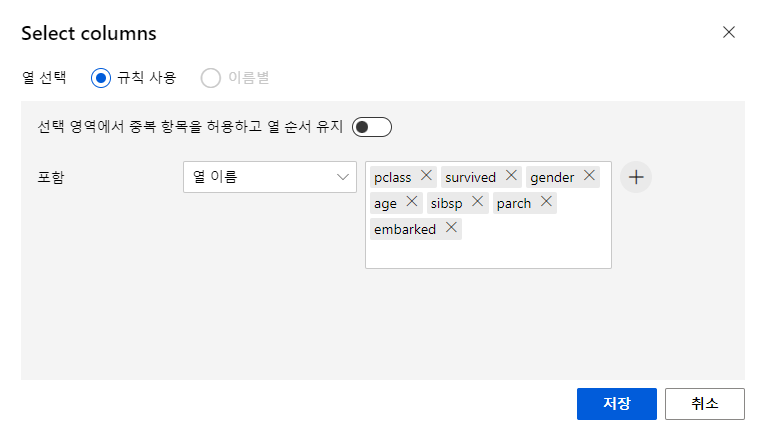
열이름들을 쭉쭉 입력후 저장
다했으면 우측상단에 구성 및 전송을 누른다
이름입력후 나는 걍 별도의 설정안하고 바로 만들었음
작업표시이름이나 작업설명하고싶은사람만 하면됨
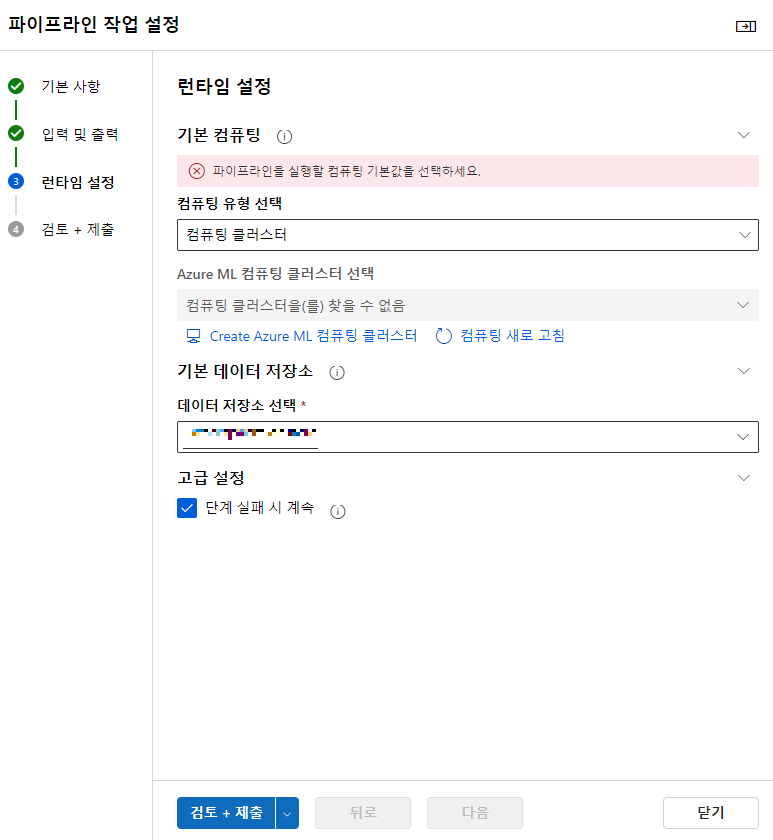
위같은 오류는 웹에서 데이터읽어서 몇몇개의 컬럼만 선택해서 작업할거면 별도의 컴퓨팅자원이 필요해서 뜨는것임
=> 컴퓨팅유형선택과 인스턴스선택에서 아까만들어둔 컴퓨팅 인스턴스를 선택해주면 됨
- 데이터저장소선택 : 머신러닝만들때 만들어놓은 저장소가 기본적으로 선택되어있어서 따로 설정안해도됨
만들기눌러서 생성하면됨
세부정보보기 들어가서 내가 드래그해놓은 Select Columns in DataSet에 우클릭 - 데이터미리보기 - Results dataset 을 누르면 타이타닉데이터를 내가 선택한 컬럼대로 데이터분류가 된것을 확인할수있다
< 문제점 >
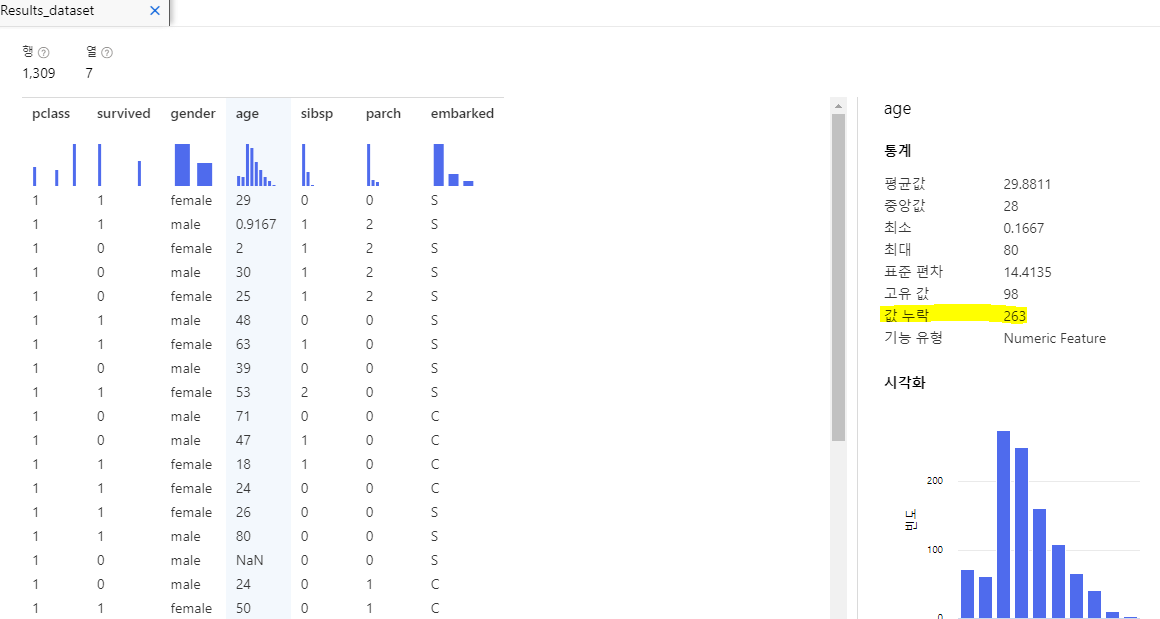
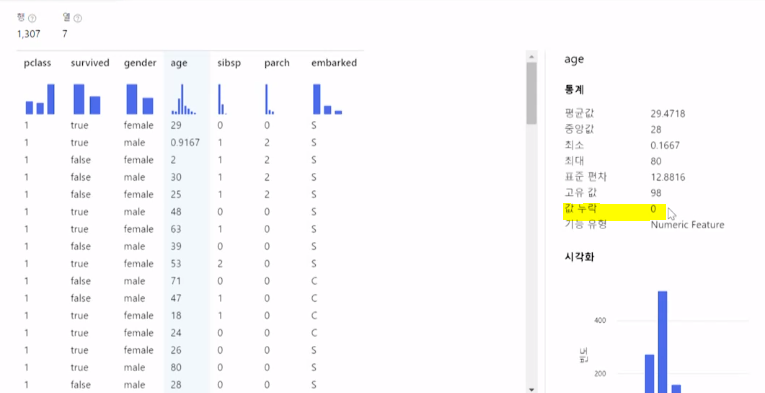
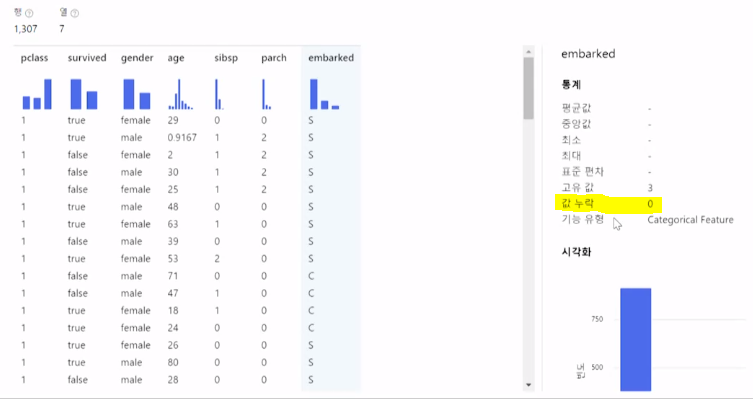
결과를 데이터미리보기 - Results dataset 로 확인해보니 문제점이 생겨버렸다,,
1) 값누락이 생겨버렸고
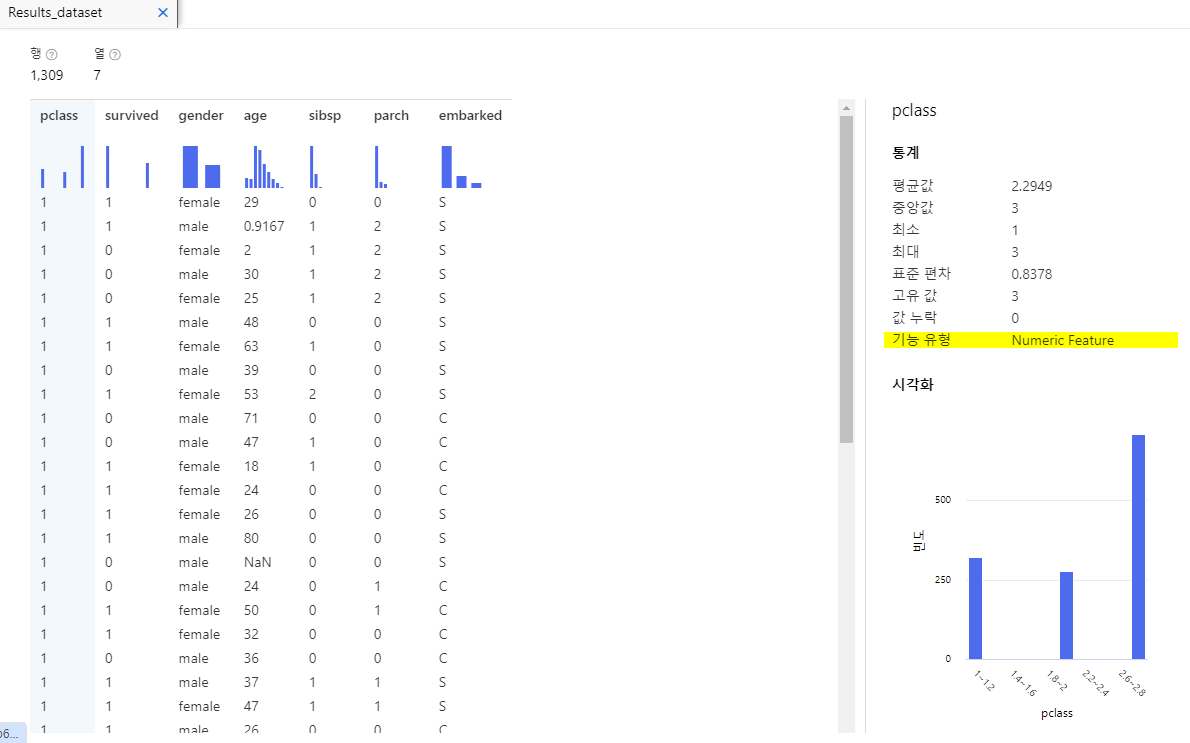
2) 몇몇 커럼의 유형이 Numeric Feature, String 으로 되버림
=> 값누락이 단 몇개라도 생겨버리면 정상적인 데이터 처리가 불가함
=> pclass와 survived,gender,embarked 컬럼의 유형도 수정해야함
정리하면 바꿔야할 문제점은 값누락과 별도의 기능유형변경이 필요하다는것이다
< 값누락 해결방법 >
Clean Missing Data 를 드래그래서 끌어놓고 드래스해서 화살표연결후 더블클릭해서 아까처럼 열편집클릭
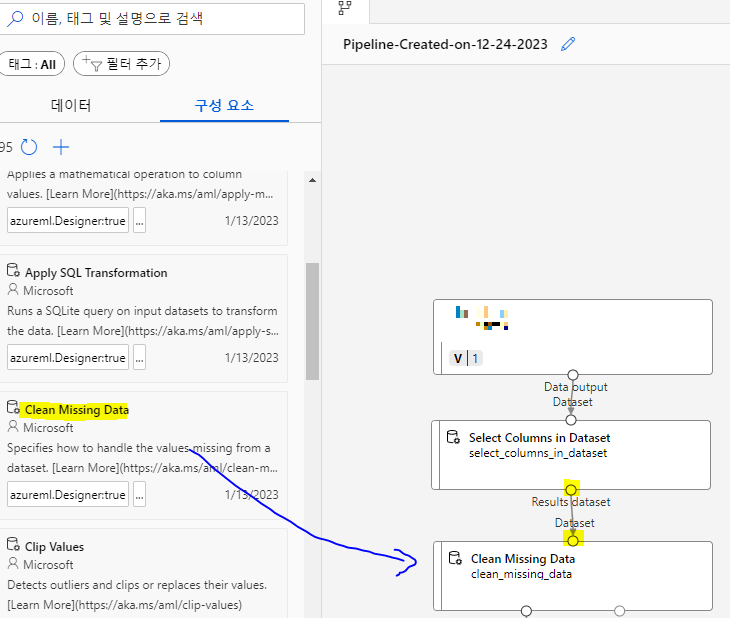
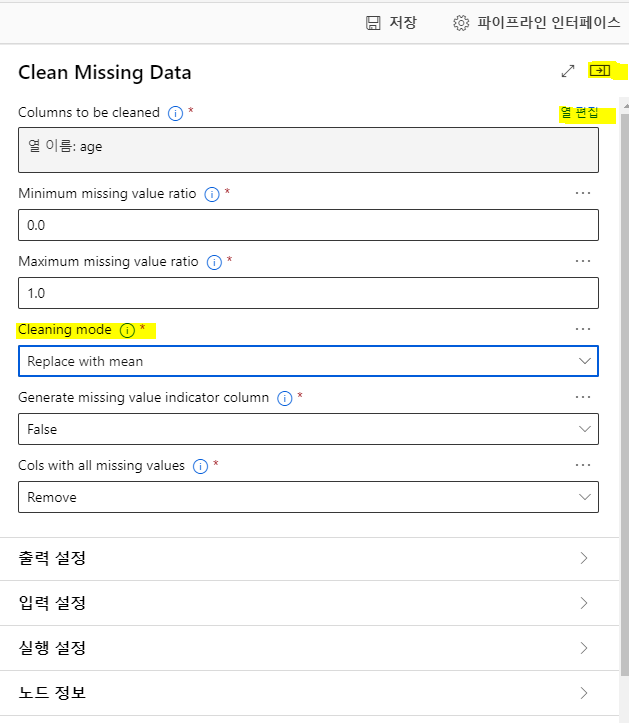
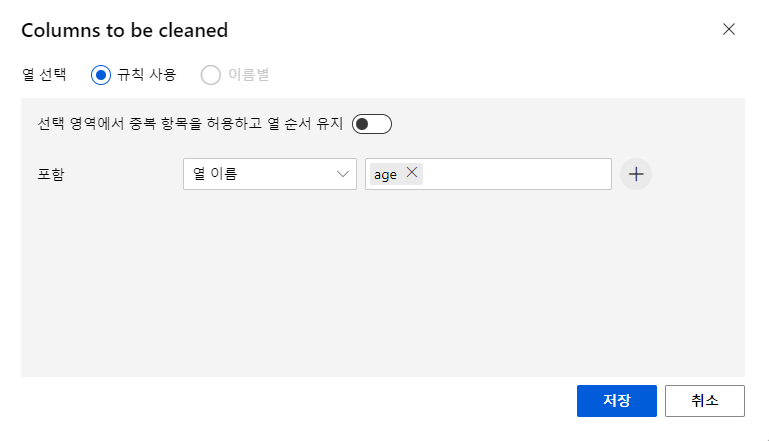
열편집에서 age를 선택하고 저장후,
Cleaning mode 를 Replace with mean 선택
(누락되지않은 값중에서 중앙값으로 대체해달라는뜻)
두번째 Clean Missing Data 를 똑같은 방식으로 또 드래그해서 화살표로연결하는데,
Cleaned datas를 연결해야한다
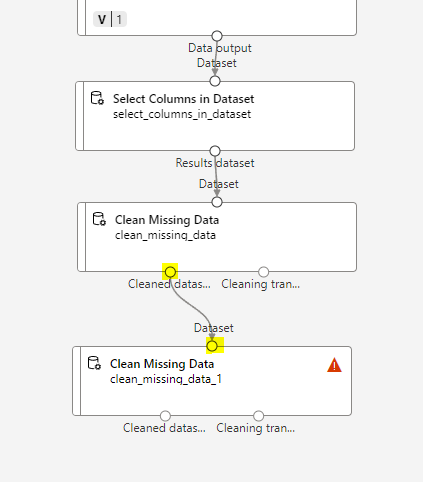
빨간화살표뜨니까 똑같은 방식으로 더블클릭해서 열편집클릭
이번에는 출항지인 embarked 를 설정할것임
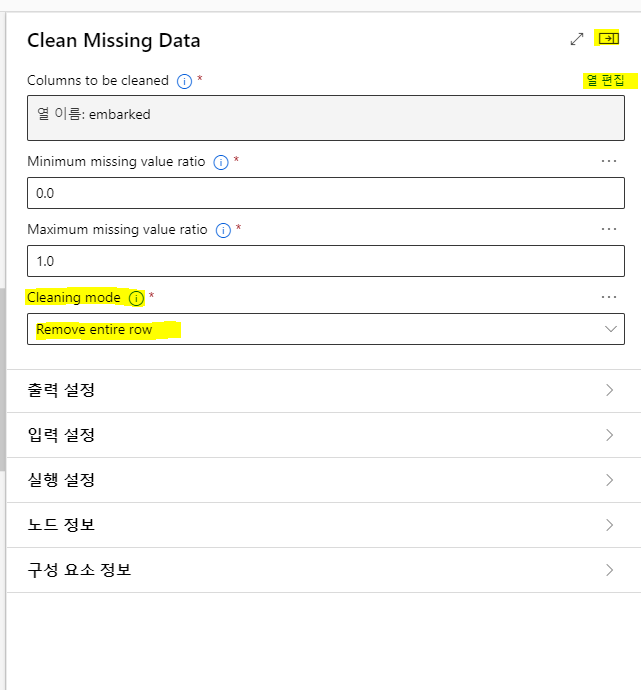
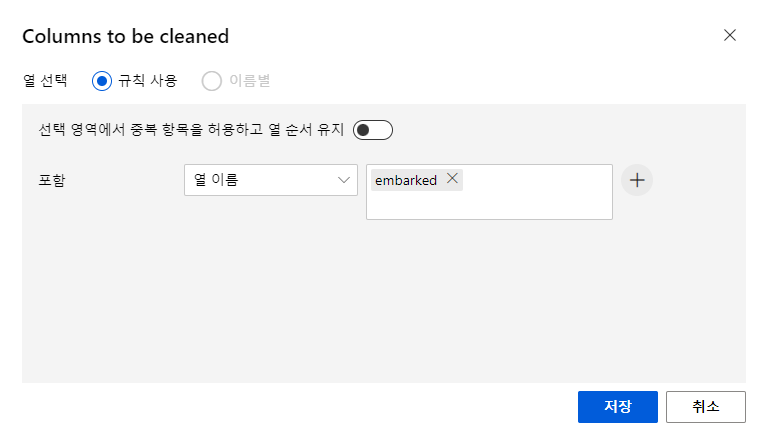
먼저 열편집을 해주고,
Cleaning mode 를 Remove entire row 를 선택한다
두건의 누락이있는 두명의 승선자를 모두 삭제
수치도 아니고, 건수가 적어서 두행을 제거함으로써 데이터누락을 제거할것임
< 수치가 아닌데 수치화된 데이터처리 해결방법 >
pclass, gender, embarked 이 3개의 컬럼은 수치화된 데이터가 아닌데 수치화처리가 되버려서 수정이 필요함
위작업에 이어서 구성요소에서 Edit Metada를 드래그해서 끌어놓고 동그라미를 드래그해서 연결시킨후 마찬가지로 더블클릭해서 열편집을 해준다 !
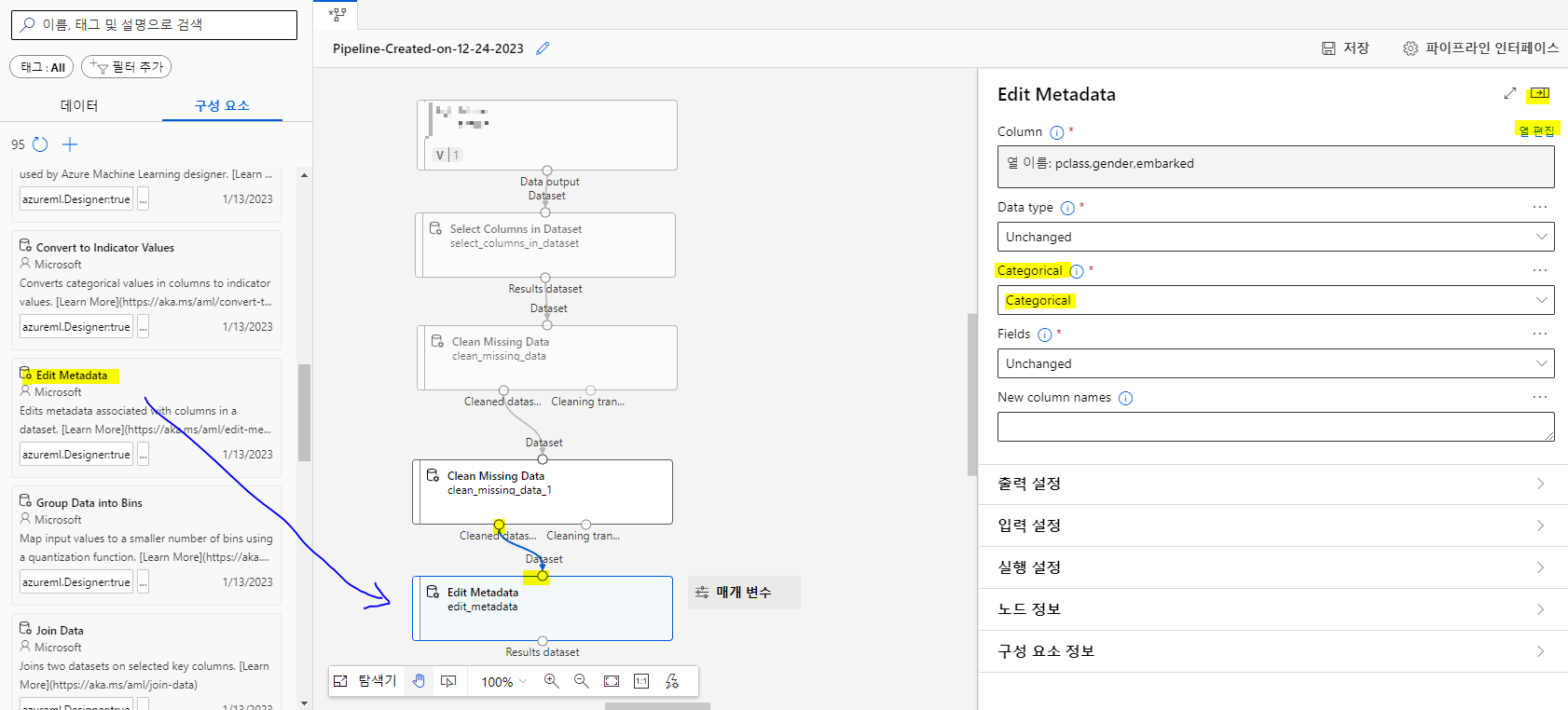
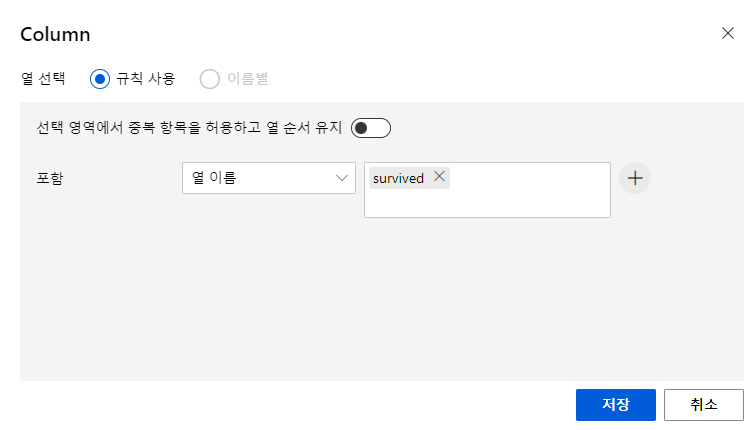
열편집을 눌러서 수정할 컬럼명을 입력한다
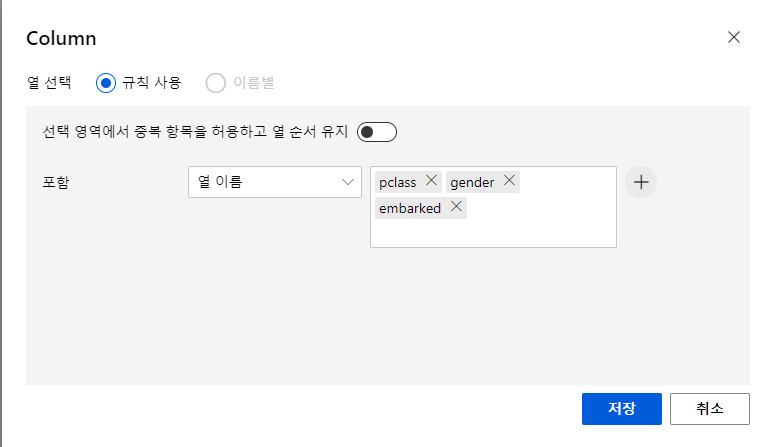
저장후
Categorical부분을 Categorical로 선택해주고, 열편집 위에있는 나가기버튼누르면됨
또
Edit Metada를 드래그해서 끌어놓고 동그라미를 드래그해서 연결시킨후 마찬가지로 더블클릭해서 열편집을 해준다
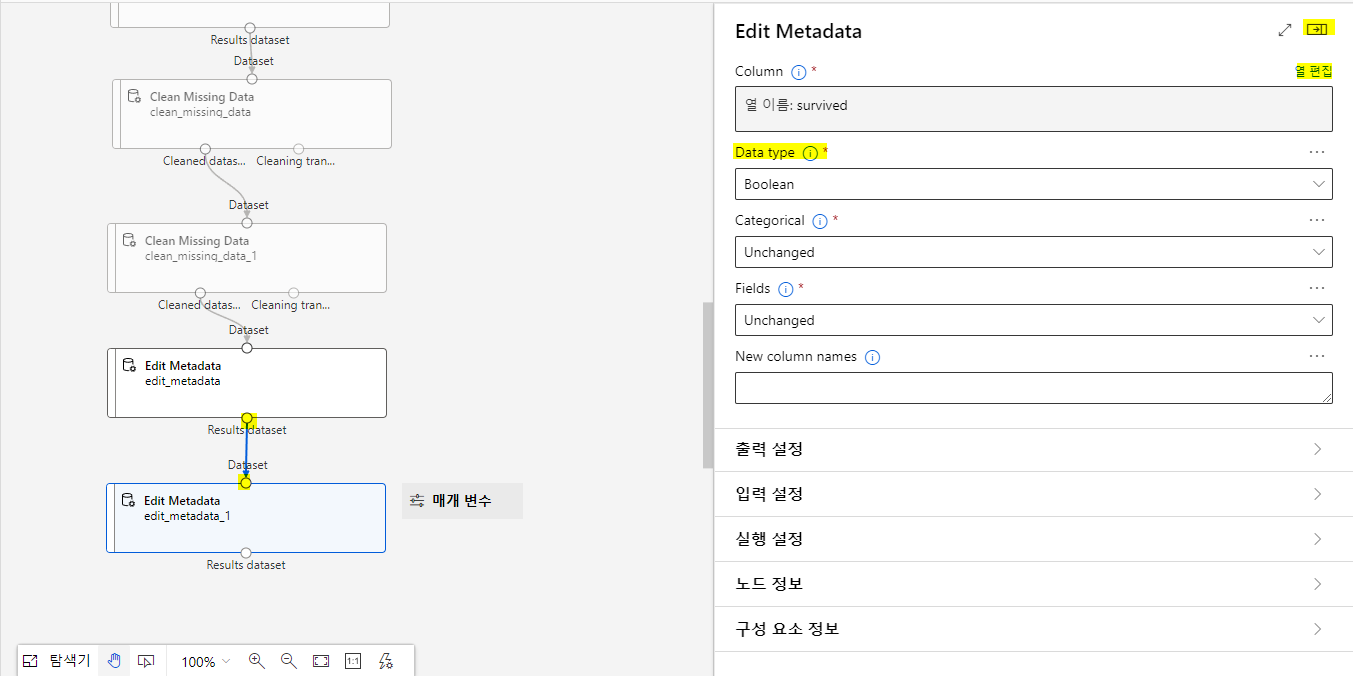
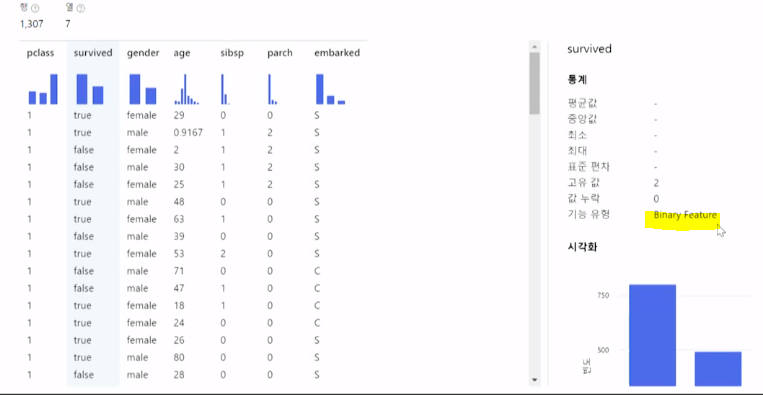
survived 컬럼은 생존,사망 두가지로 이분법적으로 나타낼거라 Data type을 불리언으로 선택하고 열편집위에 나가기버튼클릭
최종적으로 수정이 다됐다 ㅎ 이제 확인해볼차례!
< 수정결과 >
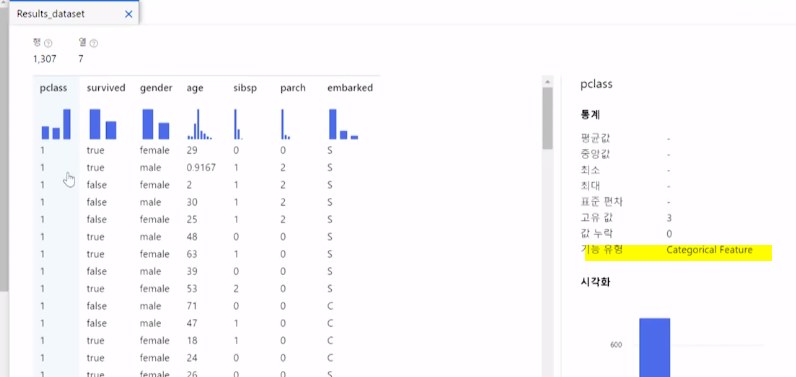
우측상단에 구성 및 전송 - 제출을 클릭
맨아래 연결해준 Edit Metada 우클릭 - 데이터미리보기 - Results dataset 를 눌러 결과를 보면 전면 수정된것을 확인할수있다 !
==================================================================
점점 글이 길어져서 2탄에서 추가적으로 더 포스팅할 예정임ㅎ